Chapter 1 of Neural Networks and Deep Learning by Michael Nielsen presents the following question. How should we choose a vector of changes (of fixed magnitude) in order to minimize  or, to analogize, suppose you are at the top of a hill looking to find the fastest way down. What direction should you take a step towards in order to bring you closer to the bottom of the hill the quickest?
or, to analogize, suppose you are at the top of a hill looking to find the fastest way down. What direction should you take a step towards in order to bring you closer to the bottom of the hill the quickest?
Using Cauchy-Schwarz:

In the interest of minimization, suppose the two vectors are linearly dependent. Then by the equality case of Cauchy-Schwarz

We know  for constant
for constant  (from the linear dependency) and the dot product of the two vectors is negative thus they “point” in opposite directions with
(from the linear dependency) and the dot product of the two vectors is negative thus they “point” in opposite directions with 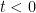 and we can say
and we can say  . So the choice that decreases our cost function the fastest for a fixed step of size
. So the choice that decreases our cost function the fastest for a fixed step of size  is
is  for some small, positive
for some small, positive  .
.

Leave a comment